

Power BI Dataflow – An exciting tool to work with when it comes to bringing up the level of scalability and continuity for your BI reports. The best part is – Dataflows don’t depend on your physical systems to connect and produce datasets, it’s more of an offering from Microsoft to reduce the overhead burden of putting asynchronous efforts to recreate datasets again and again.
If you’re wondering how dataflows can improve the overall reliability of keeping things easy, the below pointers will help you wonder:
- A common Workspace to collaborate between individuals and the development team without needing to set up the dataset over and over for different reports
- A Centralized Data model to keep you up to speed on your reporting progress over a period among several resources
- Multiple Data connectors to scale your Data model visibility and improve the performance of running queries and scripts in the Power BI cloud
- Shared Dataset concept and Self-service data preparation easily achieved while setting up for Enterprise level Reporting scheme
- Freedom from multi errors and issues cropping up during the Report development phase of things and thereby strengthening the Project architecture
Below is an example screenshot of data connectors available as a part of Dataflow implementation on the Power BI Service platform:
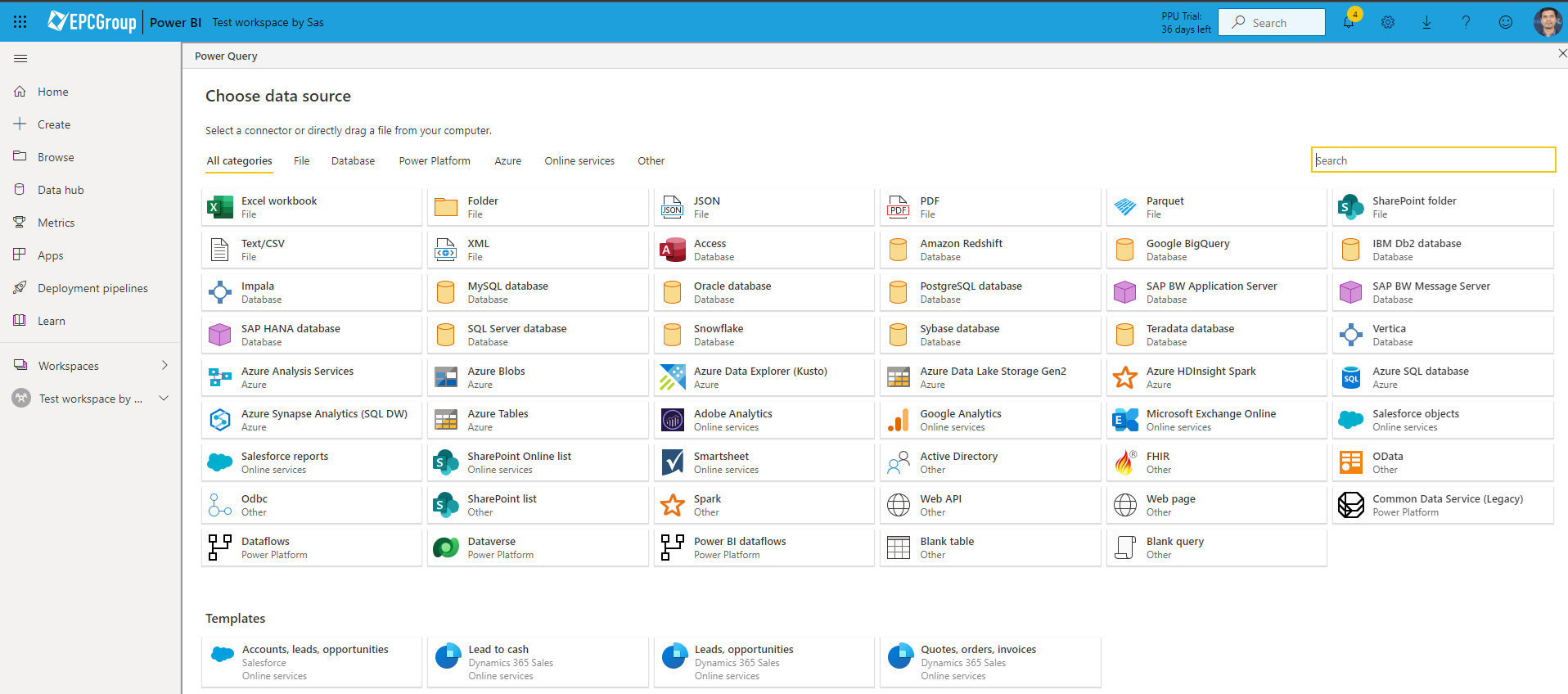
Understanding Best Practices Implementation in Dataflows
If you’re looking to scale up, the first thing that comes to our mind is – What are the pros and cons of achieving such an implementation and how should we avoid the pitfalls by following the best practices guidelines.
The answer is simple – follow the data preparation techniques that best suit your data model scalability. If you have worked in data quality and have started to explore the numerous areas where you can bring errors while loading your initial imports – this is where things improve.
Below are steps and guidelines that can help:
- Start Building out in Production Workspaces: This is the area I like to focus on. If you’re testing out your flows in Dev Workspaces, we strongly recommend you follow all data principles in cleaning your errors out in a preliminary environment before getting them moved to Production spaces using Deployment pipelines.
- Implementation of Data Warehousing Techniques: The creation of a staging layer that supports the intermediate flow of new data from primary dataflows helps in reducing the burden on source systems like Azure SQL and thereby benefitting costs
- Reduce your transformation logic to minimal: Sure this helps! The less number of steps it takes to clean up your source data points, the more optimized and faster the run will be for the initial flows to query your sources and subsequent refreshes.
- Understanding your Common data points between Workspaces: Identify those data tables that need to be reused over a period of time in different reporting solutions and this may need your capability to add similar common dataflow connections that can act as a central point between the refresh schedules
Data Modelling Skills to refine Data load errors and query operations:
One way to make your data loads faster is to perform query logic behind the walls of data endpoints. If you perform complex ETL operations during the run of Dataflow imports, it significantly affects the performance in fine-tuning the load times. It is therefore a best practice to keep common Data flows between Workspaces and reduce the query transformation steps as light as possible between them.







