

Azure Data Factory is a cloud-based data integration service that helps to create, schedule, and manage data pipelines. It allows businesses to combine data from various sources and formats, making managing and processing large amounts of data easier. With Azure Data Factory, businesses can create data-driven workflows to automate data movement and transformation activities.
One of the main benefits of using Azure Data Factory is its ability to support both on-premises and cloud-based data sources. This means businesses can easily integrate data from various sources, including legacy systems, to create centralized data storage in Azure. ADF also offers a simple drag-and-drop interface, making creating and managing data pipelines easy.
Another advantage of using Azure Data Factory is its scalability. The service is designed to handle large-scale data integration projects, making it easy to manage and process large amounts of data. Additionally, ADF is a cost-effective solution for businesses of all sizes, allowing businesses to pay only for what they use.
Overview: The AZURE DATA FACTORY V1
Azure Data Factory V1 was the first version of Microsoft’s cloud-based data integration service that allowed businesses to create, schedule, and manage data pipelines. It was released in 2015 and has since been superseded by Azure Data Factory V2, which provides more advanced features and improved scalability.
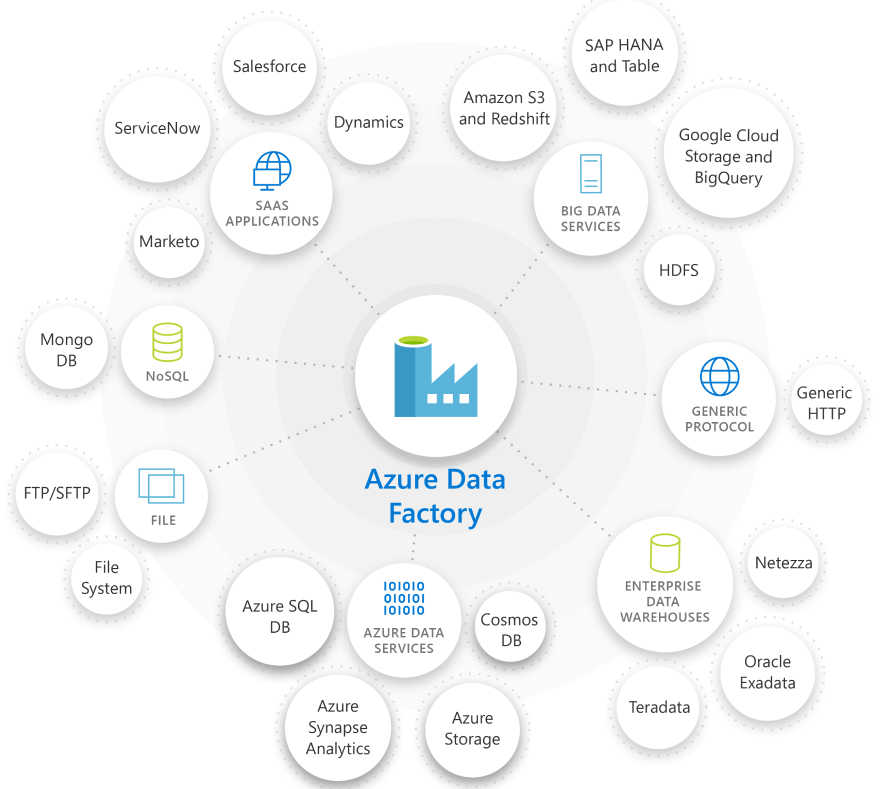
Azure Data Factory – Orchestrating activities in a pipeline
An Azure Data Factory pipeline is a logical grouping of activities used to move and transform data. Each activity represents a specific task, such as copying data from one location to another, transforming data, or loading data into a destination. Activities can be chained together in a pipeline to create a sequence of tasks executed in order.
| Frequency of Activities | Low Frequency | High Frequency |
| Azure Data Factory provides a range of activities that can run in the cloud and helps businesses automate their data movement and transformation tasks. For example, a copy activity can move data from an Azure blob storage to an Azure SQL database. The activity can be configured to perform various data transformation tasks, such as mapping columns, filtering rows, and converting data types. | $0.48 per activity per month | $1 per activity per month |
| Azure Data Factory provides a self-hosted integration runtime (IR) that can be installed on-premises to help businesses integrate their on-premises data sources with cloud-based services. For example, copy activity can move data from an on-premises SQL Server database to Azure blob storage. Stored procedure activity allows businesses to run a stored procedure in an on-premises SQL Server database. | $1.20 per activity per month | $2.50 per activity per month |
Create a scalable Data Movement Solution in Azure Data Factory
Azure Data Factory provides a reliable and scalable way to copy data between various data stores. As the volume of data or data movement throughput needs grows, Azure Data Factory can scale out to meet those needs. Businesses can leverage data movement units (DMUs) to improve data movement performance.
Data movement units (DMUs) are parallel processing units used to improve the performance of data movement activities. A DMU logically represents a computing resource used to move data. Azure Data Factory provides five DMUs for each data movement activity by default.
| Data movement between cloud data stores | $0.25 per hour |
| Data movement when on-premises stores are involved | $ 0.10 per hour |
Configure Inactive Pipeline in Azure Data Factory
Requires a specific date/time range be provided for each pipeline deployed to specify an active data processing period. The pipeline is active during this period, even if its activities are not running.
The idle period for the pipeline is any time outside of the specified range. If a pipeline is inactive for an entire month, it will be charged $0.80 per month. However, if a pipeline is inactive for only a portion of a month, it will be charged on a prorated basis for the number of inactive hours during that month.
To illustrate, if a pipeline’s start and end times are January 1, 2016, at 12:00 AM and January 20, 2016, at 12:00 AM, the pipeline is considered active for those 20 days and inactive for 11 days. During the 11-day idle period, the pipeline would be charged $0.80, prorated for the 11 days it was inactive.
Automating the Recurring Activities in Azure Data Factory
Azure Data Factory allows activities to be rerun, such as if the data source was unavailable during the scheduled run. The cost of re-running activities varies depending on where the activity is executed. Re-running activities in the cloud cost $1.370 per 1,000 re-runs, while on-premises reruns cost $3.425 per 1,000 re-runs.
To illustrate the cost implications of activity reruns, consider a data pipeline with two low-frequency activities running once daily. The first is a Copy activity that transfers information from a local SQL Server database to an Azure blob. The second is a Hive activity that executes a hive script on an Azure HDInsight cluster. It takes 2 hours per day to move the data from the SQL Server database to Azure blob storage. The table below shows the costs associated with this pipeline:
| First activity (copying data from on-premises to Azure) | |
| Data Movement Cost (per month) | 30 days per month x 2 hours per day x $0.10$6 |
| Orchestration of Activities Cost (per month) | $1.20 |
| Subtotal (per month) | $7.20 |
| Second activity (a Hive script running on Azure HDInsight) | |
| Data Movement Cost (per month) | $0 |
| Orchestration of Activities Cost (per month) | $0.48 |
| Subtotal (per month) | $0.48 |
| Total activities (per month) | $7.68 |
The Data Factory Pricing Calculator is a tool that allows users to calculate charges for specific usage scenarios. It considers the various charges associated with using Azure Data Factory, such as the cost of executing cloud and on-premises activities.
It’s worth noting that the first five cloud and on-premises activities are free of charge. The pricing for activities mentioned earlier assumes that the user has already used five cloud and five on-premises activities in other pipelines during the month.
Overview Of The Azure Data Factory V2
Azure Data Factory V2 makes it easy to collect and process data from various sources, including cloud and on-premises data sources. It provides seamless integration with other Azure services, such as Azure Functions and Azure Stream Analytics, making it an ideal choice for organizations looking to build complex data processing workflows.
Data Pipeline Pricing Models Explained
In Azure Data Factory; pipelines are made up of discrete steps known as activities and serve as the control flow for these activities. Users are charged for data pipeline orchestration based on activity run, while activity execution is charged based on integration runtime hours.
One example of an activity in a Data Factory is the copy activity, which allows for secure, reliable, performant, and scalable data transfer across various data stores. As data volume or throughput needs increase, the integration runtime can be scaled out to meet these demands.
| Type | Azure Integration Runtime Price | Azure Managed VNET Integration Runtime Price | Self-hosted Integration Runtime Price |
| Orchestration | $1 per 1,000 runs | $1 per 1,000 runs | $1.50 per 1,000 runs |
| Data movement Activity | $0.25/DIU-hour | $0.25/DIU-hour | $0.10/hour |
| Pipeline Activity | $0.005/hour | $1/hour (up to 50 concurrent pipeline activities) | $0.002/hour |
| External Pipeline Activity | $0.00025/hour | $1/hour (up to 800 concurrent pipeline activities) | $0.0001/hour |
Understanding Data Flow Execution and Debugging
Data Flows are a crucial feature of Data Factory that allows users to create data transformations at scale in a visual, user-friendly environment. However, users should note that they will be charged for Data Flow cluster execution and debugging time per vCore-hour, with a minimum cluster size of 8 vCores.
During the public preview of Change Data Capture (CDC), these artifacts are billed at General Purpose rates for 4-vCore clusters. CDC objects utilize the same data flow compute infrastructure and are executed on a single node of four vCore machines. Users can benefit from the same Data Flow Reserved Instance pricing discount when utilizing CDC resources.
| Type | Price | One Year Savings in Reserved (%) | Three-year Savings in Reserved (%) |
| General Optimized | $0.193 per vCore-hour | N/A | N/A |
| General Purpose | $0.274 per vCore-hour | $0.205 per vCore-hour ~25% savings | $0.178 per vCore-hour ~35% savings |
| Memory-optimized | $0.343 per vCore-hour | $0.258 per vCore-hour ~25% savings | $0.223 per vCore-hour ~35% savings |
Successfully Launch A Data Factory Operations
Azure Data Factory entities, such as datasets, linked services, pipelines, integration runtime, and triggers, support read/write operations that include create, read, update, and delete. These operations allow users to efficiently manage their data processing workflows and make necessary changes as needed.
In addition to read/write operations, users can monitor pipeline, activity, trigger, and debug runs. These operations include get and list, which provide users with insights into the status and progress of their data processing activities.
| Type | Price | Examples |
| Read/Write | $0.50 per 50,000 modified or referenced entities | Read or written entities of Azure Data Factory |
| Monitoring | $0.25 per 50,000 run records retrieved | Monitoring of Pipelines, activity, triggers, and debugging runs. |
Azure Data Factory V1: FAQ
How to Schedule a Pipeline in Azure Data Factory?
The Pipeline Scheduling tool in Azure Data Factory is designed to help you manage and schedule your pipelines.
The Pipeline Scheduling tool provides the following features:
- Schedule a pipeline before its execution and view its status at any time.
- View the status of a single pipeline or multiple pipelines.
- Schedule a pipeline based on a time-based trigger (for example, every 30 minutes).
- Schedule a pipeline to run at a specific time of day.
Can An Activity In A Pipeline Consume Arguments That Pass Through The Pipeline?
Yes, activity in an Azure Data Factory pipeline can consume arguments that pass through the pipeline. Arguments can pass dynamic values to activities at runtime, allowing for more flexible and customizable pipelines.
To consume an argument in an activity, you can use the expression language in Data Factory to reference the argument value. The expression language allows you to reference pipeline parameters, variables, and values in the pipeline context.
Azure Data Factory V2: FAQ
How To Handle null Values In An Azure Activity Output?
Handling null values in Azure Data Factory activity output is essential to ensure that downstream systems or activities correctly process data. Null values can cause errors and data inconsistencies if not handled correctly. Azure Data Factory provides various ways to handle null values, including using conditional statements, default values, or handling null values in the downstream system or activity.
Using a conditional statement to check for null values is a common approach to handling null values in Azure Data Factory activity output. This allows you to perform a different action or skip an activity if the output of the previous activity is null. You can use the expression language in Data Factory to create conditional statements that check for null values.
How To Use The Other 90 Dataset Types in a Data Factory?
Azure Data Factory supports over 90 dataset types, including many sources and destinations, such as databases, files, and cloud services. To use these dataset types in a Data Factory pipeline, you must first create a dataset for the source or destination you want to use.
To use the other 90 dataset types in a Data Factory, you must understand the dataset properties and how to configure them. Microsoft provides documentation and tutorials on using different dataset types in Azure Data Factory, and community resources and forums are available for additional support and guidance.
Our Azure Consulting Services Help You Find Lower Prices with Data Factory
Azure Data Factory is a powerful data integration service that can help you to reduce costs by automating data movement and transformation at scale. By leveraging its capabilities, you can optimize data processing, reduce data integration costs, and save time.
To learn more about leveraging Azure Data Factory to lower costs, consider consulting with a Microsoft-certified Azure partner, such as EPC Group.
Our Azure consulting services are designed to help organizations adopt and leverage Microsoft Azure effectively. Our certified Azure experts have extensive experience designing, implementing, and managing complex Azure environments across various industries.
EPC Group’s Azure consulting services cover many areas, including Azure architecture and design, cloud migration, data integration, DevOps, security, and compliance. We can help organizations assess their current infrastructure and identify areas for improvement, develop a comprehensive Azure strategy, and implement and manage Azure solutions tailored to their unique needs.
Fill In The Form For – FREE 30 Mins Azure Data Factory Consulting







