

Microsoft is one of the few businesses that has made it their purpose to be at the forefront of this industry. Data is the new oil. Thanks to Microsoft Azure Machine Learning, data scientists and developers can use predictive analytics to turn data into insights. Azure Machine Learning offers the easy extraction of actionable insights and the operationalization of those findings by facilitating developers’ use of predictive models in end-to-end applications.
Azure Machine Learning is a critical part of the new Cortana Analytics suite that empowers you to transform raw data into actionable insights. Using Machine Learning Studio, data scientists and developers can quickly build, test, and develop predictive models using state-of-the-art machine learning algorithms. In addition, you will learn about the critical components of an experiment and all about the Gallery of machine learning models in the product.
Building Smart Experimentation In Azure Machine Learning Studio
Machine Learning Studio lets you build models quickly and iterate on their design. For example, when building an experiment, it is common to iterate on the design of the predictive model, edit the parameters or modules, and run the experiment several times. Often, you will save multiple copies of the experiment (using different parameters).
As soon as you launch Machine Learning Studio, you’ll see that it is set up as follows:
- Experiments: Experiments designed, carried out, and saved in draught form. These consist of a collection of sample experiments with the service to assist you in getting your projects off the ground.
- Web Services: A list of your published web services for experiments. Up until you publish your first experiment, this list will be blank.
- Sets: A list of representative datasets included with the package. You can use these datasets to educate yourself about Azure Machine Learning.
- Trained Models: A list of all trained models that you have saved from your tests. No one will respond when you first sign up to be on this list.
- Settings: This is a group of options for configuring your account and resources. This option allows you to share your workspace in Azure Machine Learning with other users.
Data is a crucial part of machine learning, and it is not just about the data you have to work with for training your predictive model. You also have to make sure that the data has been transformed and analyzed before you can use it as input for training your predictive model. The process of transforming, analyzing, and preprocessing the data is known as data manipulation and statistical functions.
As you develop a model, you undergo an iterative process where you use various techniques to understand the data, identify the critical features, and tune the machine learning algorithms based on these features. Then, you continuously iterate on this until you get to the point where you have a trained and practical model that can be used.
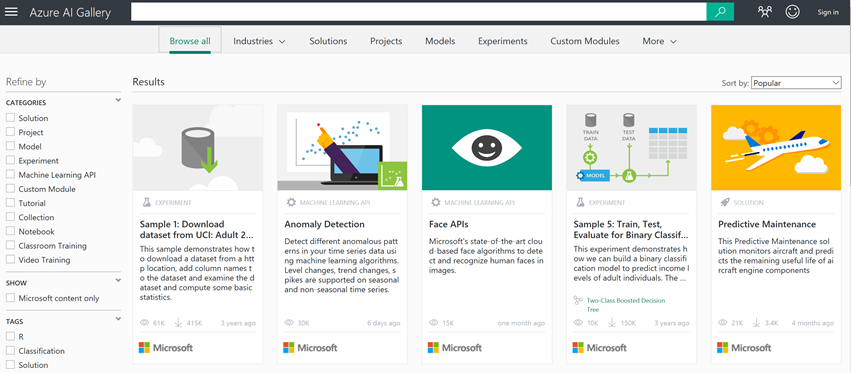
Get Started With The Gallery Of Sample Models in Azure Machine Learning
The Azure Machine Learning Gallery is a collection of sample models you can use to start machine learning. Each model contains an experiment provided by Microsoft, its partners, or individual data scientists. In time you too can publish your models in this Gallery if you share your work with the data science community.
The Gallery is a great way to start quickly since it offers sample solutions to many common problems such as fraud detection, face recognition, recommendations, churn analysis, or predictive maintenance. In addition, these samples serve as templates you can use to kickstart your projects instead of starting from scratch. For example, if you are building a new model for churn analysis, the templates in the gallery offer sample experiments that show the key steps and modules you should use in your experiment.
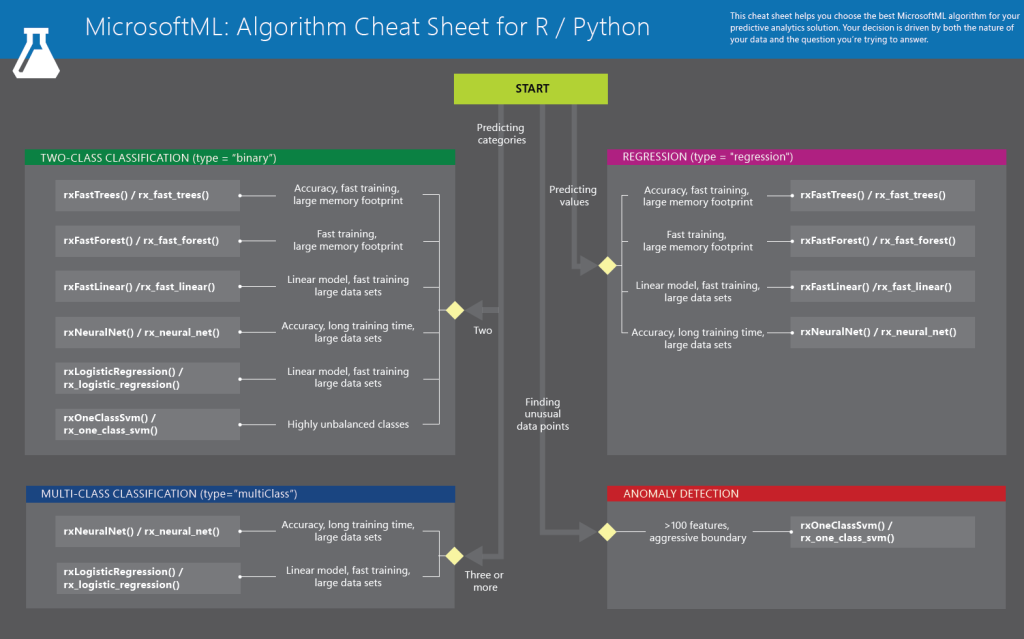
Microsoft Azure Machine Learning Algorithm Reference
We will act as a reference for some of the most often applied algorithms in Microsoft Azure Machine Learning. We will quickly discuss several techniques, including support vector machines, Bayes point machines, neural networks, decision trees, boosted decision trees, and k-means for grouping. For some of the algorithms you’ll run into in the remaining chapters of the book, this will serve as a solid basis and source of information. These algorithms are divided into the following categories by us:
- Regression Algorithms
- Classification Algorithms
- Clustering Algorithms
Regression Algorithms
Let’s start with the most frequent regression strategies in the Azure Machine Learning service. Regression techniques predict response variables with numerical outputs, such as estimating a car’s miles per gallon or a city’s temperature. Input variables can be either numeric or categorical. However, these algorithms have in common that the output (or response variable) is numerical.
We’ll review well-known regression approaches, such as linear regression, neural networks, decision trees, and boosted decision tree regression.
Linear Regression
One of the first prediction methods in statistics is linear regression. To predict the outcome given a collection of observable independent variables, linear regression aims to fit a linear model between the response and independent variables.
Neural Networks
Artificial neural networks are a collection of algorithms that reflect how the brain functions. Backpropagation networks, Hopfield networks, Kohonen networks (also known as self-organizing maps), and adaptive resonance theory (or ART) networks are a few examples of numerous neural network techniques.
Decision Trees
Decision tree algorithms are hierarchical methods that divide the dataset repeatedly according to specific statistical criteria. Decision trees aim to reduce the variance inside each node and maximize the variance across various nodes in the tree.
Boosted Decision Trees
Ensemble models are a type of boosted decision tree. Like other ensemble models, Boosted decision trees use many decision trees to create better predictors. Individual decision trees may all be poor forecasters. However, they perform better when combined.
Classification Algorithms
A form of supervised machine learning is classification. Using labeled training data, the objective of supervised learning is to infer a function. The label for a new dataset can then be determined using the function (where the labels are unknown). Decision trees, logistic regression, neural networks, support vector machines, naive Bayes, and Bayes Point Machines are just a few categorization techniques we can employ to develop the model.
In cases where the label is unknown, classification techniques are employed to forecast the label for input data. Classes, groups, and target variables are other names for labels. A telecom business could want to forecast the following, for instance:
- Churn: A customer’s tendency to transfer from one telecommunications provider to another.
- Customers’ Propensity to Buy: Willingness to Purchase New Goods or Services.
- Upselling: Persuading customers to purchase more expensive services or add-ons.
Clustering Algorithms
Unsupervised machine learning includes clustering. The objective of clustering is to put comparable objects in one group. The majority of currently used cluster algorithms fall into the following categories:
- Divide a dataset into k separate data parts. A cluster corresponds to each partition.
- Using a dataset as their starting point, hierarchical clustering techniques can build clusters from the bottom up or the top down. In the bottom-up method, also called the agglomerative method, each item in the data set is first assigned to a single cluster by the algorithm.
- Clusters are grown using algorithms considering the density (number of objects) in each item’s “neighborhood.” They are frequently used to locate clusters with “arbitrary” forms. In contrast, the majority of algorithms that use partitioning rely on the usage of a distance metric.
EPC Group for Azure Consultancy Services
In this blog, we learned about the different components of an experiment. In addition, we also learned about three preset machine learning algorithms available in Azure Machine Learning. These accessible and easy-to-understand datasets can be a good starting point for new product users. If you want a modern, talented company to manage your Azure workloads, finding a Microsoft partner who focuses on managing the Azure environment and with the expertise to customize your plans is crucial. EPC Group has these specific skill sets and can bring a lot to the table when it comes to helping you maintain a thriving cloud environment.







